Tools
首页
画图
音乐
采集
记事
博客
实验室
登录
lypeng
146
文章
11
分类
48
记事
分类
生活-[23]
Linux-[24]
前端-[9]
数据库-[16]
PHP-[31]
git-[7]
其他-[6]
python-[20]
算法-[4]
React-Native-[4]
中草药-[2]
广告位1
广告位2
首页
/ PHP
返回列表
QueryList文章采集练习
阅读:4789
发布:2017-09-14
作者:lypeng
之前用querylist练习过,但是没有完整的做过东西,这次抓取简书的一些文章,做一个完整的站点,再练习一下tp5。最简单的三个页面,首页、列表、详情,去掉不实用的banner等等多余的东西,简简单单就好~ 效果预览:<a href="http://news.dpshop.net" target="_blank" class="btn">查看demo</a> #文件与数据库结构 文件结构,开始想写个后台的,分了home,admin两个组,最后感觉没必要,去了! 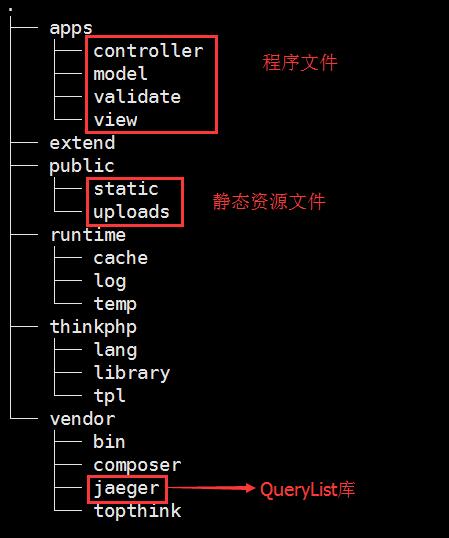 数据库结构 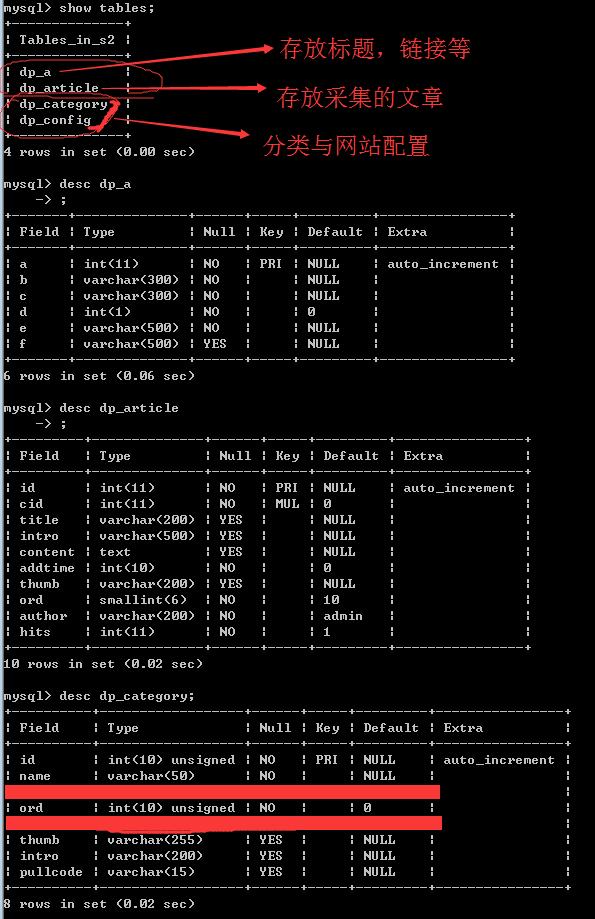 dp_a表说明 a--------->递增字段 b--------->文章标题 c--------->链接地址 d--------->专题分类 e--------->采集状态(0未采集,1采集成功,2采集失败) f--------->保留,未使用 #前期准备 前期,进简书的热点专题页面(<a href="http://www.jianshu.com/recommendations/collections?utm_medium=index-collections&utm_source=desktop" target="_blank">http://www.jianshu.com/recommendations/collections?utm_medium=index-collections&utm_source=desktop</a>),挑选了20个专题,(初步筛选规则:关注人数在700k以上,另外加了两个程序员与上班这点事儿) 以下为专题与关注人数对比表格 | 专题 | 关注人数(单位k) | | --- | ---- | |社会热点|774| |散文|1140| |诗 |955| |历史|883| |摄影 | 872| |运动健身| 725| |漫画 |764| |IT互联网|719| |读书|1615| |短篇小说|1263| |心理|1230| |旅行在路上 | 1208| |青春 | 1130| |想法 | 986| |美食 | 941| |哲思 | 921| |谈谈情说说爱| 909| |奇思妙想| 808| |上班这点事儿| 670| |程序员 | 449| 注意每一个专题链接都类似下面这样,例如心理:<a href="http://www.jianshu.com/c/8fQvXW" target="_blank">http://www.jianshu.com/c/8fQvXW</a> , 这个8fQvXW需要保存下来,暂且叫他pullcode,保存到分类表里面。 #代码部分 ##采集步骤 1. 新建一个项目s2,配置域名www . s2 . com ,下载tp5,加载querylist库 `composer require jaeger/querylist` 2. 采集文章链接:http :// www . s2 . com/caiji/cjlist/page/1/cid/1.html 3. 采集文章内容,这里可以按分类或者按ID获取,一次10篇循环,或者一次一篇,两种方式都尝试了,但是感觉一次一篇能更好点。:http :// www . s2 . com/caiji/getone/id/1.html 4. 采集后的处理(时间与缩略图) 5. 前端部分,首页,列表,详情,三个页面,自适应手机端,访问网址:<a href="http://news.dpshop.net" target="_blank">http://news.dpshop.net</a> ##代码开始 ```php <?php namespace app\controller; use think\Controller; use think\Db; use QL\QueryList; class Caiji extends controller { /** * 采集列表主程序,传入参数page,cid * page-->起始页数 cid-->分类ID */ function cjlist($page,$cid){ $p=10;//计划采集页数 $pullcode=$this->getpullcode($cid);//获得专题code码 $url=$this->geturl($pullcode,$page);//获得抓取网址 $this->getlist($url,$cid);//开始抓取列表 if($page>$p){ exit('end'); }else{ //跳转下一页 $this->success($page.' ruku',url('caiji/cjlist', ['page' => $page+1,'cid'=>$cid])); } } /*查分类表,得到专题对应code*/ function getpullcode($cid){ $carr=Db::name('category')->find($cid); $pullcode=$carr['pullcode']; return $pullcode; } /*拼凑采集的专题网址*/ function geturl($pullcode,$page){ $url="http://www.jianshu.com/c/".$pullcode."?order_by=added_at&page=".$page; return $url; } //获取简书的标题与链接 //a--主键递增,b--标题,c--链接,d--分类,e--状态 function getlist($url,$cid){ if(empty($url)){ exit('url error'); } $baseUrl = 'http://www.jianshu.com'; $data = QueryList::Query($url,array( 'b' => array('.content .title','text'), 'c' => array('.content .title','href','',function($urlb) use($baseUrl){ return $baseUrl.$urlb; }) // 'f' => array('.wrap-img img','src')//文章缩略图,采集完后处理 ))->data; // var_dump($data); foreach ($data as $k => $v) { //入库 $data[$k]['b']=$v['b']; $data[$k]['c']=$v['c']; $data[$k]['d']=$cid; $data[$k]['e']=0; //内容采集状态,0-尚未采集内容 $lastid=Db::name('a')->insert($data[$k]); if($lastid){ echo $v['b']."success!<br/>"; }else{ echo $v['b']."error!<br/>"; } } return true; } /* * php使用curl判断404 */ function chkurl($url){ $handle = curl_init($url); curl_setopt($handle, CURLOPT_RETURNTRANSFER, TRUE); curl_setopt($handle, CURLOPT_CONNECTTIMEOUT, 10);//设置超时时间 curl_exec($handle); //检查是否404(网页找不到) $httpCode = curl_getinfo($handle, CURLINFO_HTTP_CODE); if(($httpCode == 404)||($httpCode == 599)) { return false; }else{ return true; } curl_close($handle); } /*逐条采集文章内容,完成后自动跳转到下一篇,直到结束*/ function getone($id='1'){ if($id=='2587'){ exit($id);//到最后一篇+1时结束 } \think\Loader::import('vendor.jaeger.phpquery-single.phpQuery'); $value=Db::name('a')->where('a',$id)->find(); if(!$this->chkurl($value['c'])){ //页面不存在,修改已采集状态为2 Db::name('a')->where('a',$value['a'])->update(['e'=>2]); $this->success($value['a'].'==='.$value['b'].' not ok!',url('caiji/getone', ['id' => $id+1]),'',1); }else{ $html=file_get_contents($value['c']); } // 规则开始 $rules=array( 'title'=>array('h1','text'),//标题 'author'=>array('.info .name','text'),//作者 'intro'=>array("[name='description']",'content'),//摘要 'addtime'=>array('.publish-time','text','',function($cc){ $cc=trim(str_replace('.', '-', $cc),''); return strtotime($cc); }),//发布时间 'content'=>array('.show-content','html','div a',function($content){ $doc = \phpQuery::newDocumentHTML($content); $imgs = pq($doc)->find('img'); foreach ($imgs as $img) { //让图片地址以http开头 $src=strpos(pq($img)->attr('src'),'http')===false ? 'http:'.pq($img)->attr('src') : pq($img)->attr('src'); //过滤掉一些不合格的图片地址,采集过程中发现的! if((substr($src,0,4)=='http')&&(strpos($src,'applewebdata:')==false)&&(strpos($src,'webkit-fake-url:')==false)&&(strpos($src,'x-apple-ql-id:')==false)){ $localSrc = UPLOADS_PATH.'caiji/'.md5($src).'.jpg'; $contentSrc = '/public/uploads/caiji/'.md5($src).'.jpg'; if($this->chkurl($src)){//检测图片是否存在 $stream = file_get_contents($src); file_put_contents($localSrc,$stream);//将内容中的图片保存到本地 pq($img)->attr('src',$contentSrc);//替换内容中的图片src地址 } } } return $doc->htmlOuter(); }) ); $data = QueryList::Query($html,$rules)->data; $data['0']['cid']=$value['d']; $res=Db::name('article')->insert($data['0']);//采集结果入库 if($res){ Db::name('a')->where('a',$value['a'])->update(['e'=>1]);//修改采集状态为成功! $this->success($value['a'].'=='.$value['b'].'is ok!',url('caiji/getone', ['id' => $id+1]),'',1); } } ```  4.采集之后的处理 1).时间 有些文章的发布时间结果为0,替换为当前时间。 2).缩略图,使用内容中的第一张图片作为文章缩略图 关键代码如下,采用正则匹配 ```php $id=1; $info=Db::name('article')->find($id); preg_match('/<img src="(.*)"/isU', $info['content'],$arr); if(!empty($arr['1'])){ $data['thumb']=$arr['1']; }else{ $data['thumb']='/public/static/images/nopic.jpg'; } $res=Db::name('article')->where('id',$id)->update($data); ```
------本文结束
感谢阅读------
上一篇:
微信支付总结(一)前期准备
下一篇:
thinkphp自带的消息队列think-queue学习测试
 lypeng lypeng
lypeng lypeng